
Tree Transformers
A step towards generalizing the transformer architecture

After a billion architectures and a trillion variations, I finally found a transformer architecture that intrigued me. And this essay is step one towards the theory and the sub-field on which it was built1.
I.
The representation of any dataset that we wish to approximate/predict/learn the distribution of, has converged to be vectors. This phenomena was not by accident, as vectors provide higher dimensional representations of the data, which is needed for mapping connections between data points, and also plays right into the strengths of a GPU, giving us incredibly parallelizable algorithms for deep learning. While these points are very true and have bore incredible fruits, we can always benefit by probing further.
Every dataset has a unique internal structure2 which our models must approximate, in order to learn and predict. This structure, in the process of transforming it into a vector representation is lost (or, is very costly to preserve).3
What happens if, instead of transforming the dataset into a vector representation, we instead try to preserve what structure we have, and generalize the transformer in order to perform the operation on that structure itself, instead of vectors ?
II.
As the title suggests, the first data structure I chose to explore was the ubiquitous tree structure4 . Trees appear more often then any other structure in computer science (except maybe graphs), and hence I chose to implement the self-attention mechanism, but for trees, before anything else.
We first begin by defining a Node data structure, like so,

but with a crucial difference: it’s stored value can be another node, recursively. This structure itself becomes the essence of the deep network structures we care about: as matrix is a vector of vectors, so can this structure give us a “tree of trees“. This is essential while defining the very important outer-product or matrix multiplication equivalent for the tree data structure.
The next step would be to define three very important functions which we will use in order to construct the self-attention mechanism. The functions are5:
Pair : this function answers the question, how do we define an operation over two tree structures, i.e, how do we add/subtract/multiply/divide two trees ?
Counit : this function is analogous to the reduce function, or, a meaningful way to transform the tree data structure into a single scalar. A reduction operation.
Map : a very well known function. Basically given a function and a data structure (where the structure is strictly a collection of values), the map function applies the function to the entire collection.
Defining these three function for any data structure should essentially unlock the self-attention mechanism for that structure, hence we shall start with these three first, but for our Tree structure.
Starting off with the Pair function, it should be a simple traversal and adding up the values of two trees:

Next is the Map function, which is extremely straightforward:

Now, before we write the last Counit function, we must define a simple Tree structure, which helps in storing the reduced value in it’s state.

Equipped with these three functions, we are all set for defining our own self-attention mechanism, on our way to write the tree-transformer !
III.
Now we must focus on the very basics of what operations go into creating a simple neural network (say a multi-layered perceptron) and build up to the operations required for self-attention, and see how they can be defined when the underlying data structure is not a vector, but a tree.
First, we start with defining the dot product for the tree structure. The most important things that we have to keep in mind are that the transformation preserves the shape of the input vector, and that the weight vector here is a “vector of vectors“ also called a matrix. Each column in the matrix undergoes a reduce operation, before being multiplied by the input’s columnar value. This principle is to be followed in our tree structure as well: first we reduce (using the Counit) the inner tree of the weights (remember, our weight tree is a tree of trees) and we then proceed to multiply it with the input tree’s node.
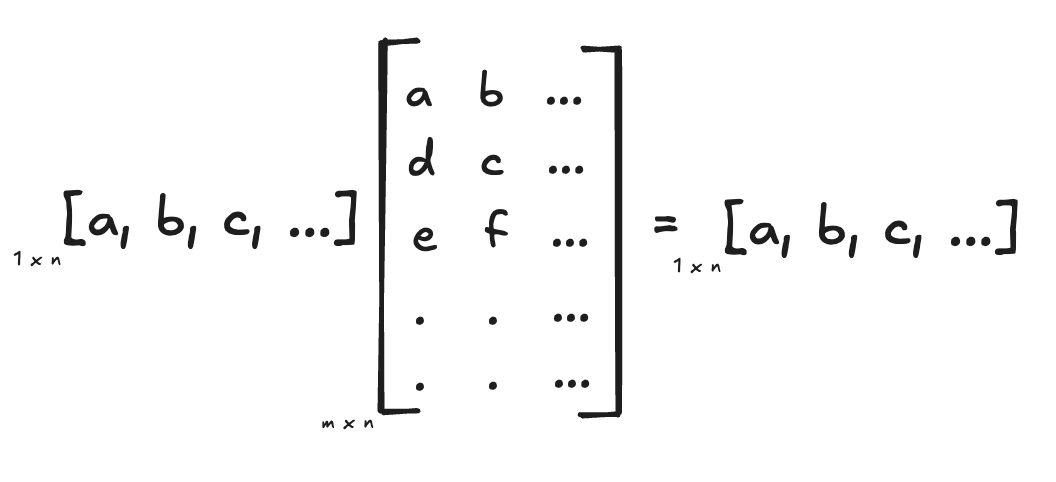
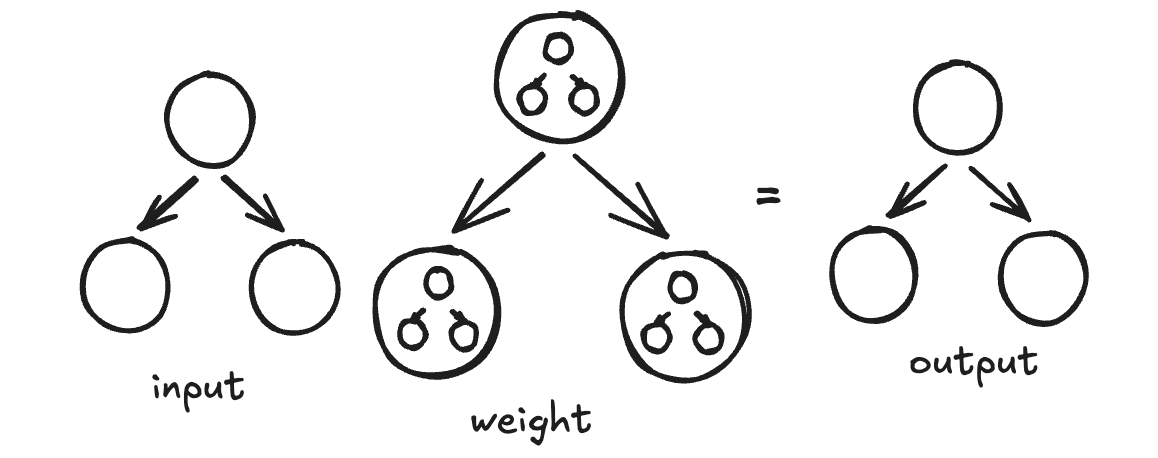
Implementation:

With the dot product out of the way, we are getting ever closer to defining the self-attention function. We simply need one last function, which would help us create a tree of trees, that is, the outer product.
The procedure is very simple: given two trees, we simply need to “insert“ the second tree, into each node of the first tree, with the node’s value being multiplied throughout the inner tree. This is analogous to the outer-product for vector-vector multiplication.
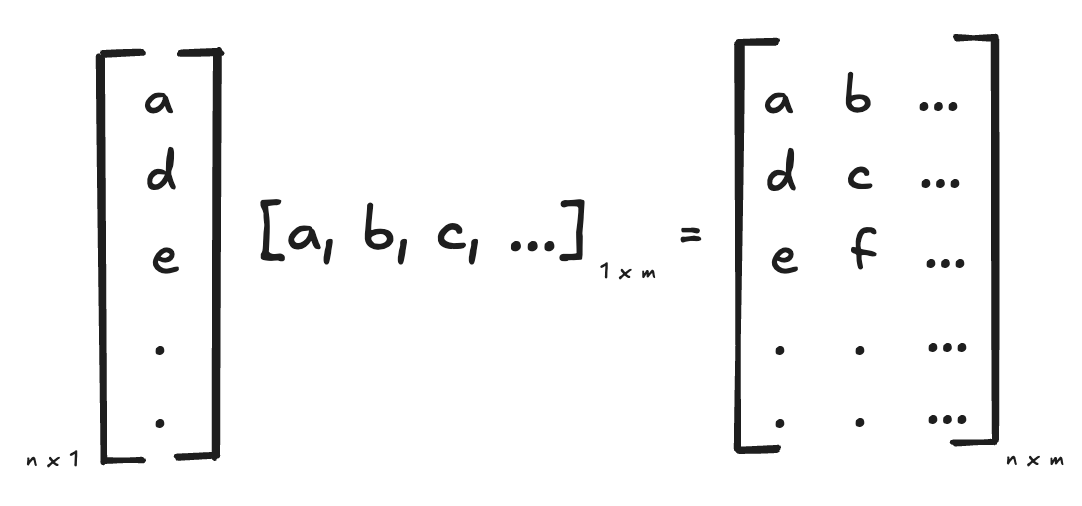
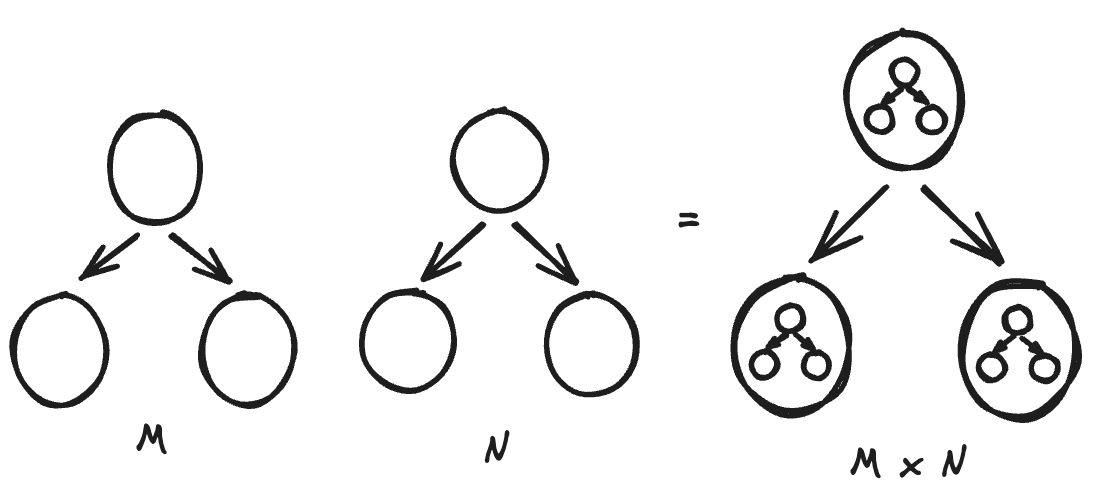
and here’s the very straightforward implementation.

With these function in place, we can define both the multi-layered perceptron and the self-attention mechanism. Without further ado, here are both implementations6:

And there we have it. The self-attention mechanism for a tree data structure, where the representation never changes. This is far from a generalized transformer we talked about, since this operation is very specific to the tree data structure, but by implementing it here, it became clear that the three functions we defined were the primary/atomic functions, upon which we can define a self-attention function for any structure. And while Python may not be the best language to handle a true generalization, we can learn a lot from these implementations, before moving on to higher level languages (like Haskell, as the authors in the paper have used).
IV.
By creating the tree transformer, my aim was to understand the kind of operations I would require in order to generalize the self-attention mechanism, and get a better idea about how these operation can be defined for other data structures (as the authors have suggested).
While defining them in this manner is a fun learning experience, my true aim is two-fold: progress my way towards the actual Haskell implementations, and move up a level of abstractions to understand the category theoretic side of it all, and one the other end, to understand how to write custom GPU kernels for these, by learning to mimic Pytorch Geometric and Deep Graph Library. After which, I can either try to implementation the same operations in MLX, or go a step further then geometric deep learning and explore Topological Deep Learning.
This is an exploratory series of blogs I’m planning to write in the future. Thank you for reading this far, subscribe to follow the series !
For anyone interested or wants to know where I got the idea from, this is the paper/blog.
Here I mean a mathematical structure.
An example of when the structure is lost is if we decide to embed code for example, in a vector. In the transformation process, the graphical structure of the code is lost, and is flattened into a vector. In case of words/text, on the other hand, we have to train separate embedding models in order to find good vector representations, using a pre-determined vocabulary set, which is costly.
I’ve essentially implemented a binary tree, with n=2 child nodes.
For the first two functions, I’ve borrowed the names from the blog mentioned. The Map function is a well-known concept in programming or functional programming.
The self-attention is in-complete without the softmax operation :
